Wstecz


W niniejszej serii przedstawię kompleksowy zestaw artykułów, z których każdy skupi się na istotnym aspekcie tego zagadnienia.
Seria obejmie kilka części, z których każda będzie stanowić spójną całość. Każdy artykuł będzie skoncentrowany na jednym zagadnieniu, a razem utworzą pełny przewodnik po optymalizacji zarządzania stanem w środowisku React.
W dzisiejszym świecie aplikacji internetowych, efektywne zarządzanie stanem staje się kluczowym wyzwaniem dla programistów. Szczególnie w kontekście aplikacji reactowych, gdzie dynamiczne interakcje i płynne doświadczenia użytkownika są priorytetem, a skuteczna obsługa stanu stanowi kamień węgielny projektów.
Systematyka stanu aplikacji
Zacznę od określenia, czym de facto jest stan aplikacji. Stanem może być oczywiście mnóstwo rzeczy, ale my podzielimy stan według klucza skąd pochodzi. I mamy stan serwera, i stan klienta. Stan pochodzący z serwera, to wszystkie dane, które trzeba załadować, na przykład API restowym albo GraphQLem. Frontend z reguły powinien być tylko interfejsem umożliwiającym wykonywanie tych operacji. Kiedy Frontend pobierze dane z serwera teoretycznie te dane mogą być już nieświeże, tak zwane stale data. Dlatego Frontend jako interfejs w jakiś sposób powinien obsłużyć synchronizację danych. W tym celu można zastosować różne techniki, między innymi caching. I w przypadku Frontendu chaingującego dane, mamy tak naprawdę dwa źródła danych: Backend jako taki oraz frontendowy cach. Mamy wreszcie stan po stronie klienta. Stanem są przede wszystkim dane, jakie użytkownik wpisuje w formularzach. A także to, co się potem dzieje z tymi danymi, kiedy użytkownik przechodzi przez proces biznesowy. Stanem po stronie klienta jest także URL i wszystkie parametry w nim zawarte (zamiast wchodzić do aplikacji przez stronę główną, możemy wejść na konkretny link i wówczas Frontend sczytuje parametry z URL-a i wykonuje odpowiednie akcje). Dodatkowo, stanem może być cokolwiek, co wyklika użytkownik.
Stan aplikacji można podzielić także ze względu na charakterystykę jego zarządzania. Weźmy za przykład paginację w gridzie. Komponent rodzic obsługuje zmianę strony, tworzy callbacka `setPage` i przekazuje go do komponentu dziecka. W podejściu active, kiedy zmieniamy stronę, musimy dodatkowo wiedzieć, że należy przeładować także dane. W kodzie jest logiczna zależność pomiędzy numerem strony, a faktycznymi danymi, jakie grid wyświetla. Z kolei w podejściu reactive deklarujemy tą zależność wprost. Dodatkowo - oddzielamy działanie od jego konsekwencji. Tyle, że musimy mieć jakiś silnik, który to obsłuży i ten silnik rozumieć. Co na początku nie jest proste.

Następnie możemy wśród stanów wprowadzić podział ze względu na ich widoczność. Stan nazwiemy prywatnym jeśli jest zamknięty w obrębie jednego komponentu. Gdy stan jest współdzielony lub przynajmniej widoczny przez wiele komponentów zaklasyfikujemy go do grupy stanów współdzielonych. Zasadniczo, opłaca nam się trzymać stan jako prywatny, o ile to możliwe. Wówczas im mniej komponentów ma do niego dostęp, tym mniej komponentów może od niego zależeć.
Wpływ zależności komponentów od stanu pociąga za sobą istotne konsekwencje. Jeśli stan współdzielimy, to siłą rzeczy jego właścicielem będzie komponent zawieszony wysoko. Wysoko w aplikacji albo wysoko w jakimś module. W każdym razie, kiedy ten stan się zmieni, renderuje się właściciel i ciągnie za sobą rendery w dół (w zależności od tego czy współdzielenie będzie zbudowane na zasadzie props drillingu, context API czy np. Redux rerendery będą wyglądać inaczej)
Przy budowaniu stanów współdzielonych szczególną uwagę należy poświęcić małym komórkom stanu, które przenosi się wzwyż drzewa DOM. Konsekwencje mogą być znaczące nawet przy przeniesieniu o jedno piętro. Ujmując to inaczej jeśli stan jest prywatny, to ograniczamy zarówno niepotrzebne rendery, jak i ograniczamy zależności komponentów od stanu. Często stan nie może być prywatny. Ale zawsze warto zadać sobie pytanie, czy daną komórkę stanu dałoby się zrobić jako prywatną, bo to może wiele rzeczy uprościć.

Rozdzielmy jeszcze stany ze względu na dystrybucję. Gdy w aplikacji istnieje jedno źródło prawdy (single source of truth) to powiemy że aplikacja ma stan scentralizowany lub globalny. W aplikacjach z takim typem stanu jeśli czytamy dane, to zawsze wiadomo, skąd. A jeśli modyfikujemy, to też tylko w jednym miejscu. Zaletą centralizacji jest to, że skoro nie ma innych miejsc, które przechowują te same dane, to nie trzeba się z nikim synchronizować. Po drugiej stronie mamy stany rozproszone. W takich aplikacjach możemy mieć wiele źródeł prawdy. Wówczas, jeśli chcemy coś zmienić i chcemy zachować spójność danych, to trzeba aktualizować wiele miejsc. Typowym przykładem jest REDUX VS CONTEXT.
Ostatni podział wiąże się z modyfikacjami stanu aplikacji. Albo stan zmieniany jest bezpośrednio (direct updated) albo pośrednio przez wprowadzenie eventów (indirect updated). Przy tym podziale zamiast pytać o to "Kto steruje zmianą?" zapytamy "Ile trzeba wiedzieć, aby zmianę wykonać?". W przypadku eventów - nie trzeba wiedzieć nic. Kluczowe jest tu oddzielenie faktu zdarzenia od jego obsługi. Inny kod tworzy i wysyła zdarzenie, a jeszcze inny wie, co z nim zrobić. Podejście direct to na przykład useState w hookach albo stan w komponentach klasowych. Jeśli odpalamy setter, to komponent musi wiedzieć, co z nim zrobić. Albo jeśli rodzic przekazuje dziecku gotowego callbacka i dziecko nie wie, co się dzieje pod spodem. Z drugiej strony, w przypadku useReducer, callback jest jeden - dispatch. Zdarzenia stają się wspólnym kontraktem pomiędzy providerem, a konsumentem.
Kluczowe wzorce projektowe dla zarządzania stanem aplikacji
Z pełną wiedzą na temat rodzajów stanów aplikacji przejdźmy do omówienia najważniejszych wzorców projektowych wykorzystywanych przy zarządzania stanem. Są to:
provider-consumer
publisher-subscriber
mediator
Wykorzystanie jednego z tych wzorców rozwiązuje problemy związane z wykorzystaniem najprostszego props drillingu. W tym podejściu połączenie pomiędzy komponentami współdzielącymi stan jest niebywale silne. By osłabić te powiązania wprowadzamy pomiędzy nie provider. Różnica polega na tym, że wszystkie komponenty, czy to czytające stan, czy modyfikujące go komunikują się z nim tylko przez pośrednika, ale nie komunikują się ze sobą nawzajem. I tak, Redux - ma swój provider, Reactowe Componenty - również. React Query - i wiele, wiele innych bibliotek też.
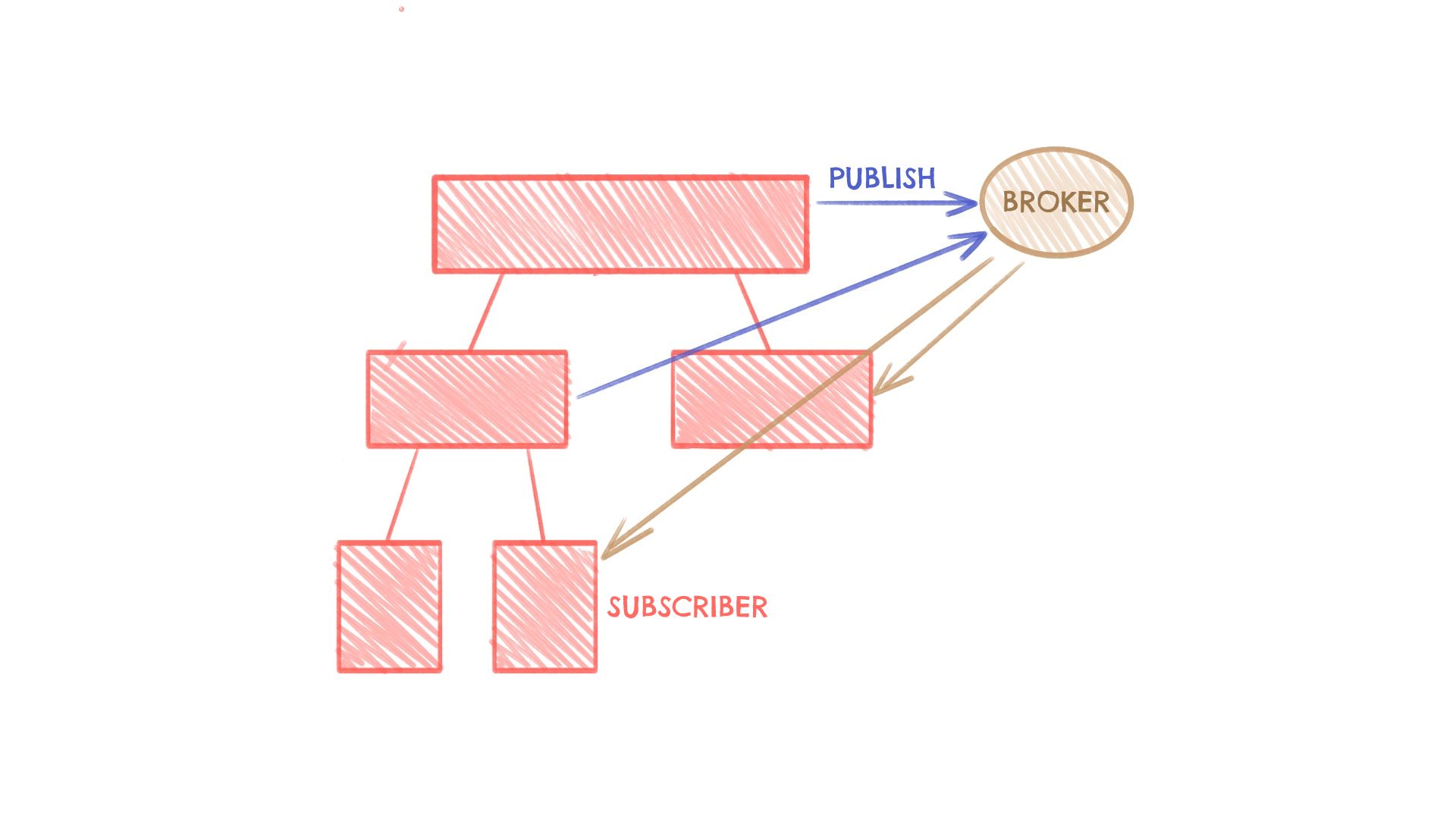
Publisher-subscriber
W najprostszym ujęciu wzorzec ten można opisać jednym zdaniem: Ten kto przechowuje stan jest jego providerem, zaś wszystkie komponenty, które z niego korzystają są konsumentami. Tych właśnie nazw: Provider oraz Consumer trzyma się React Context API.
Publisher-subscriber
W tym wzorcu niektóre komponenty nazywane publishers wysyłają modyfikacje (czytaj publikują eventy) inne zaś - subscribers - są zainteresowane tylko ich czytaniem. Broker zaś - to ten, kto trzyma dane i pośredniczy między komponentami. Należy zwrócić tu uwagę publisher-subscriber i observer, czyli obserwator, są do siebie bardzo podobne, bo i w jednym, i w drugim przypadku występuje publikowanie i subskrybowanie. Z tym, że w observerze relacja jest bezpośrednia. Publisher z subscriberem komunikuje się bezpośrednio. W publisher-subscriber pojawia się dodatkowo broker, który rozluźnia coupling.
Mediator
Ostatni z ważniejszych wzorców zarządzania stanem. Już sama nazwa mediator oddaje sposób, w jaki komponenty wchodzą ze sobą w interakcje. Mediator pozwala komponentom komunikować się ze sobą. Ponadto nie określa on, gdzie zaimplementowany jest stan, ponieważ zajmuje się wyłącznie komunikacją. Wzorzec ten ma tę zaletę, że wymaga mniej zmian, gdy aplikacja rośnie, ponieważ komponenty są niezwykle luźno powiązane. Jeden komponent informuje mediator o chęci zmiany stanu, a mediator przekazuje te informację do komponentu, który ten stan przechowuje.
Podsumowanie
Chcemy podkreślić znaczenie efektywnego zarządzania stanem w dzisiejszych dynamicznych aplikacjach internetowych. W kontekście aplikacji reactowych, gdzie interakcje użytkownika i płynność doświadczenia są priorytetem, umiejętne obsługiwanie stanu staje się kluczowym wyzwaniem dla programistów.
W kolejnych artykułach serii, zgłębimy różnorodne aspekty tego zagadnienia, zaczynając od ContextAPI wraz z szczegółowymi strategiami optymalizacji, a kończąc na omówieniu najważniejszych bibliotek związanych z tym zagadnieniem.
Zrozumienie różnych rodzajów stanów, ich zarządzania, oraz wpływu na architekturę aplikacji pozwoli nam efektywnie radzić sobie z wyzwaniami związanymi z rozwojem aplikacji w oparciu o React. Mam nadzieję, że ta seria nie tylko poszerzy Twoją wiedzę, ale także dostarczy praktycznych wskazówek, ułatwiając procesy projektowania i implementacji.



